How conscious
is your AI system?
The Functional Consciousness Score measures a system's observable capacity
to access and reason about its own internal states — not what it "feels like" to be
that system, but what it can actually know about itself.
The results reveal a hierarchy with a clear message:
current AI systems, however powerful, are operating with a fraction of human
self-awareness. The gap is not philosophical — it is numerical.
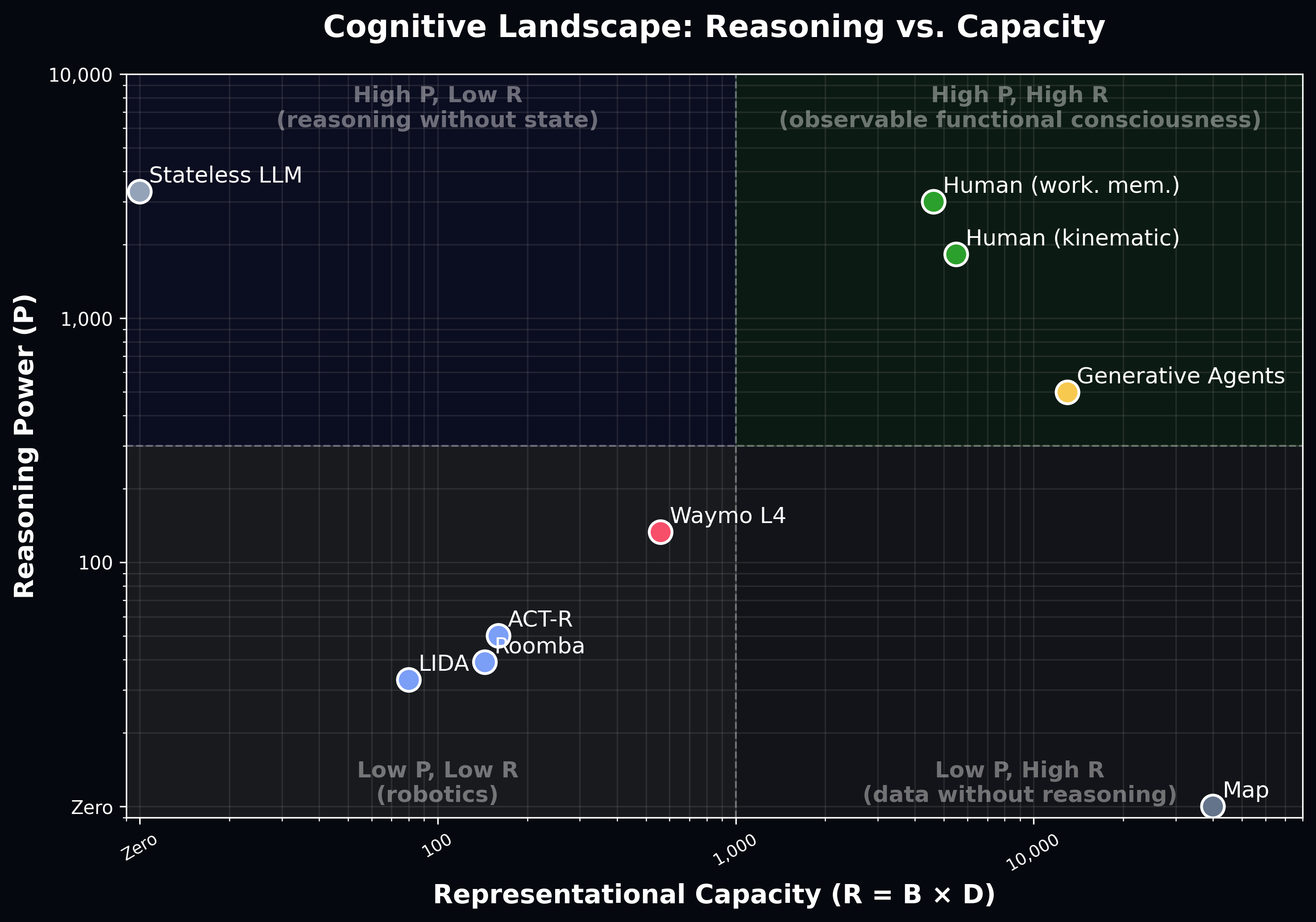
FCS = R · P, where R (Representational Capacity) measures how richly a system models its own states, and P (Reasoning Power) measures how effectively it can reason over those models.
A map has rich spatial data but zero reasoning — it scores zero. A stateless LLM (ChatGPT, Claude, ...) has immense reasoning power but no persistent self-model — it also scores zero. Functional consciousness requires both.
The multiplicative structure is intentional: either dimension alone is insufficient. Only systems that combine rich self-representation with powerful inference achieve meaningful FC scores.
| System | B vars | D̄ bits/var | P reasoning | FCS score | Scale |
|---|---|---|---|---|---|
| ~1,000 | ~40 | 0 | 0 | ||
| 0 | 0 | ~3,300 | 0 | ||
| ~20 | ~4 | ~33 | ~2,600 | ||
| ~18 | ~8 | ~39 | ~5,600 | ||
| ~20 | ~8 | ~50 | ~8,000 | ||
| ~40 | ~14 | ~133 | ~74,500 | ||
| ~130 | ~100 | ~497 | ~6.5M | ||
| ~550 | ~10 | ~1,826 | ~10M | ||
| ~330 | ~14 | ~3,000 | ~13.9M |